



I’m happy to announce that Raven’s Site Auditor now supports canonicalization. The new canonical tag support works in conjunction with our preexisting duplicate content check.
If you’ve ever wondered how Site Auditor determines which pages are duplicates and which ones are not, today is your lucky day. I’m going to explain how our tool analyzes pages for duplicate content, and also how the new canonicalization check enhances those results.
How Site Auditor Determines Which Pages Are Duplicates
On the surface, checking for duplicate content seems simple. If two pages are the same, then they’re duplicates. However, it’s a lot more complicated than that.
Many pages with duplicate content reside on pages that use different design templates. That means we can’t simply mark pages with the same HTML as duplicates.
There are also pages with duplicate content that use the same design template, but have tiny variations in text. If the Site Auditor was looking for exact matches, it would completely miss those pages.
Those are the main reasons we had to make Site Auditor’s duplicate content detection a lot smarter than a simple diff check.
When Site Auditor analyzes pages for duplicate content, it first detects the common areas of the page, like the header, footer and sidebar and ignores them. It then applies what’s called a “Simhash” algorithm to the main content of the page. If the algorithm determines that a page is 95% similar to another page, Site Auditor reports those pages as duplicates.
The Simhash algorithm was created by Moses Charikar (PDF), and is referenced in several related patents owned by Google. So we feel pretty good about this method and how it might relate to how Google detects duplicate content.
How the New Support for Canonicalization Affects the Duplicate Content Check
Canonicalization allows a webmaster to specify one page as the original or authoritative content source when there is more than one page with the same content. For example, if pages A, B and C all have the same content, you could place a canonical tag on pages A and B that point to C, and search engines like Google would know that page C is the correct page to reference for that content (thus ignoring pages A and B).
Now, when Site Auditor finds pages A, B and C, and determines they’re duplicate content, it will first check its canonical tag before reporting it as duplicate content. If pages A, B and C have canonical tags that point to themselves, Site Auditor will report all three pages as duplicates. However, if pages A and B have canonical tags that point to page C, it will not report them as duplicates.
Viewing Canonical Tags in Site Auditor
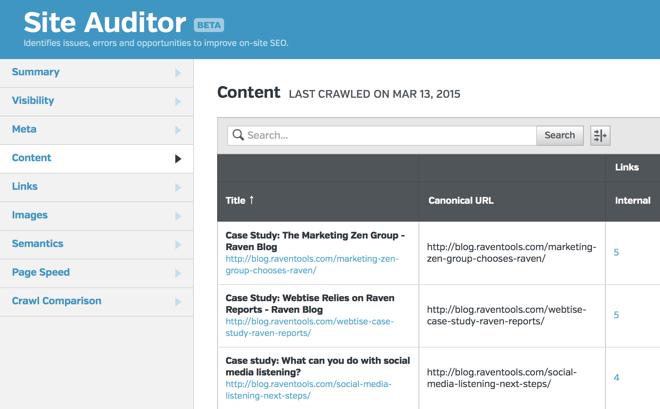
In the Content section – where Site Auditor reports on duplicate content – there is a new table column option that will display the Canonical URL for each page. For some accounts, it may not display by default. If it’s hidden, click on the Display Options icon and click on the Canonical URL checkbox.
This is what the new Canonical URL table column looks like in Site Auditor.

Analyze over 20 different technical SEO issues and create to-do lists for your team while sending error reports to your client.
Very cool that this has been added. I’ll run a report or two here and see how it reacts, but I’m looking forward to this update!
Love it. Great new feature. I look forward to future enhancements. Keep up the awesome work.
Hi Conor and Chris,
We’re excited too! Appreciate your positive feedback.
Great!
Glad to see this has been included. Looking forward to more updates.
The ability to know what you consider duplicate content would be helpful. Currently your system only says I have duplicate content, but no insight as to what to look for.
Agreed! We have a Help Desk article that explains it: https://raven.zendesk.com/hc/en-us/articles/202026994-How-does-Site-Auditor-detect-duplicate-content-
Jon,
Read the article. Would be cool if Raven had a icon you could click which would show the actual “duplicate content” so you could see what it’s referring to. As it is now, you have to speculate, look at the pages manually, etc.
This is great feedback. I’ll talk to the team about it. Thanks!