



Sometimes it’s easier to define something by explaining what it is not. Take duplicate content, for example.
Duplicate content is not inherently bad.
After all, Google, Yahoo! and Bing introduced the rel=canonical link element in 2009. When used correctly, that should be the end of the duplicate content story. Yet, confusion continues.
Syndication Stirs the Pot
LinkedIn inadvertently made this very “old news” new again when it began allowing its members to post content, original or republished, on its platform.
I embraced the opportunity. I knew that search engines can discern which web page was the original source document based on when it was crawled. Concerns regarding duplicate content didn’t enter my mind. Yet, someone asked me recently:
If I re-publish my post on LinkedIn, will I be penalized for duplicate content?
Shortly after, I was hoping to secure the role of guest contributor on a mainstream marketing blog. Because of the time investment required to write quality, original content, I asked the editor if she would be interested in republishing a few of my marketing-oriented posts. She said:
Not unless they are completely original. We don’t want to be penalized for duplicate content.
Twice now someone had voiced concern about being penalized for duplicate content.
Time to clear a few things up.
Jargon Perpetuates the Myth
First, a word about the word “penalty.”
There’s a difference between:
- penalties, which may lead to de-indexing of a web page or an entire website,
- algorithm updates, which may affect a website’s SERP rankings; and
- filtering, which means Google knows about pages but doesn’t display them in SERPs.
A penalty is strictly a manual, human action taken by Google’s web spam team. You know one when you get one. Literally. You’ll get a notice from Google Webmaster Tools.
Often, people say they have been penalized by Google when really they mean that they were affected by an algorithm update. Or they worry about penalties when really they’re afraid their content won’t rank well.
For example, Google’s Panda algorithm update affected websites with low quality content. A percentage of web pages were de-indexed or dropped in the SERP rankings by hundreds of positions. Sites guilty of publishing low quality content are often guilty of publishing excessive duplicate content too.
While you can’t know in advance if a website’s pages will be filtered, you can perform a site:websitename.com search in the Google search box to determine if pages are being omitted. This example shows 19 pages of 1,370 results (not shown) that Google knows about, so we know quite a few pages are being filtered out.

When you click on repeat the search with omitted results included for this site, a full 20 pages of URLs are being filtered! What a missed opportunity because of duplicate content issues.
I’ll say it again: duplicate content is not bad; it just needs to be managed.
10 Duplicate Content Scenarios and Their Solutions
1. You have thousands of e-commerce product pages.
Scenario: You’ve been adding new product categories to your website over the past few years and the site has become unmanageable. However, you don’t want to delete pages indiscriminately.
Solution: Google wants to know about your duplicate content. Including rel=canonical on your web pages tells Google which pages you consider to be important. For e-commerce sites, this would mean adding the rel=canonical meta tag to product pages and point them to the proper category pages. Many e-commerce sites lose considerable organic traffic when they do not use this element correctly.
2. You want to republish someone else’s content on your website/blog.
Scenario: You follow several popular bloggers whose content matches the demographics of your audience. You think it would add value to your readers by co-publishing another website’s blog post.
Solution: You can designate the original source of the content by using the rel=canonical tag. Using a popular SEO plugin makes this super easy for WordPress blogs; its creator, Joost de Valk (a.k.a. @Yoast), wrote about how to edit the canonical link element recently. We’ve done this on the Raven blog and nothing bad happened.
3. You want a printer-friendly website.
Scenario: If you offer accessible and printable versions of your website, you have a bunch of duplicate content.
Solution: Cascading Style Sheets (CSS) can handle this issue. If multiple style sheets are beyond the capacity of your web developer, there’s a simple solution. Include a link to the canonical URL in the robots meta tag along with “noindex,follow,noarchive” for your duplicate pages. (Your developer should understand that last sentence. If not, find a different developer 😉 )
4. You’re forced to republish corporate content.
Scenario: Many enterprises or franchise owners publish corporate news on their own websites, then ask you to put the same content on yours.
Solution: Create a mash-up of content. By combining content from multiple sources, you can overcome the hurdle of duplicate content. Using multiple templates and feeds lets you target your customers’ specific interests. It also helps with local SEO when your content includes regional identifiers and cultural references.
5. Your pages have identical metadata that you can’t change.
Scenario: You’re managing your website with an older Content Management System (CMS) or licensing a proprietary CMS that doesn’t allow you to use unique page title elements or meta descriptions.
Solution: Search engines pay attention to unique metadata.
If you have the same page title on your web pages, Google’s likely to generate the dreaded omitted results link shown above. Remember, this is not a penalty, but an example of filtered content. They simply do not want to clutter search results with what they interpret to be duplicate pages.
Unique page titles strongly improve your relevance for targeted searches. If your CMS prevents you from inserting unique page titles, find another CMS. It’s that important.
While meta descriptions are not essential for all pages on your website, they offer two signals: one to search engines and the other to humans. Think of the thousands of websites that sell the same product and simply copy and paste from the manufacturer’s online brochure. At a minimum, you’re not differentiating your business from every other company to the search engine or the human consumer.
6. You want to implement HTTPs on your website.
Scenario: You follow search industry news and heard that secure websites may become a Google ranking factor in the future. As one company discovered, you could create a major duplicate content issue if you improperly implement HTTPS.
Solution: Do it right the first time. We plan to take our own advice when we move our blog and main website to HTTPS (our app already is).
7. You did not resolve your domain name.
Scenario: Another all-too-common mistake is web developers not resolving the domain to one dedicated URL. This represents the surest way for a new website not to appear in SERPs. It’s an easy mistake to make.
When first setting up a website with a domain name server (DNS) like Hostgator or WPEngine, you have the option of choosing www vs. non-www hostnames. If a searcher types into a browser http://example.com/, but your client’s website was set up with http://www.example.com as the domain, Google will see this as two individual websites. Sometimes one URL will be served up and sometimes another. The confused linking structure leads to reduced search visibility.
Solution: This is an easy fix. Ask your developer to put in place a 301-permanent redirect from one to the other URL. Google will know which is the preferred canonical address.
8. Scrapers are stealing your content.
Scenario: You discover that a spammy website is outranking your website and using your content without your authorization to win the top spot in Google. We’ve all seen scraped content around the web, usually on really crappy websites filled with AdSense ads.
Solution: It’s easy enough to identify unauthorized scrapers in Google Webmaster Tools, under Your Site on the Web > Links to Your Site. In Raven, you can go to Research Central > Pages. Scan the External Links column. If you see an unusually high number of incoming links pointing to one URL, you can drill down and View URL to identify the culprit.
Often, the scraper is a bot. You can slow down bot scrapers through your .htaccess file. If all else fails, you can file a scraper report directly to Google.
9. Framers are stealing your traffic.
Scenario: You’ve been running Google AdWords for some time with great success. You begin to notice your paid search traffic has declined significantly, yet you’re still paying for ads.
Solution: Framing is a much more serious offense than scraping in the United States because it constitutes copyright and trademark infringement and violates state unfair competition laws, not to mention Google’s guidelines.
Framing allows a website to:
- Pull in the contents of an external site into the local site.
- “Chop up” the contents of the external site into different “frames” or parts.
- Display only the frames that are beneficial to the framing site.
Source: Michigan Technology and Telecommunications Law Review (PDF)
Google’s AdSense policies are clear on what constitutes copyright infringement and prohibits placing AdSense ads on:
- Pages with pirated content
- Framed content from other sites
- Pages that direct traffic or link to pirated content
Solution: Here are a few steps you can take:
- Look up the host company through Whois.
- Contact the host. They will give the website owner two days to comply.
- Contact the website owner directly and tell them to remove your content or suffer the legal consequences.
- File a DMCA (Digital Millennium Copyright Act) takedown notice.
Or get creative. When Michael Gray (a.k.a. @Graywolf) discovered an exact replica of a 2,000-word article he’d written, he sent the offender a bill via PayPal and told him he had 24 hours to pay it or remove the article. Otherwise, Michael would contact his advertisers and hosting company. The offender removed it.
10. Internal links are out of control.
Scenario: You manage a large, enterprise-level website that’s developed an unruly, overly complex navigation. Over time, internal links from various sections of the site point to similar pages. Your SEO and user experience suffer as a result.
Solution No. 1: Fixing the navigation and/or redesigning your website are the obvious, though painful, solutions.
Solution No. 2: It won’t solve the user experience issue, but an SEO-friendly alternative is to employ the rel=canonical tag to the offending pages.
First, run a website audit using Raven to identify duplicate content and the internal links pointing to those pages. Go to SEO > Site Auditor > Content. Duplicate pages are easily identified by the red Yes.
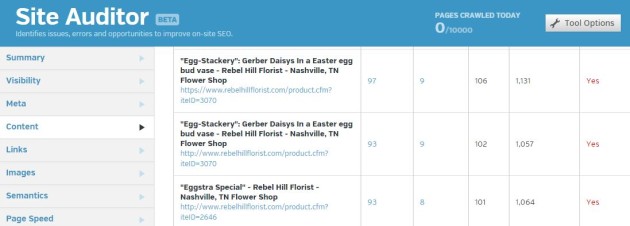
In this example, all those links pointing to duplicate pages prevents any one of those pages from ranking for a keyword/phrase. Essentially, the website is diluting “link juice” from (conceivably) 283 misplaced links.
Once you determine what should be the canonical page, adding the canonical meta tag to it will solve the problem. For the website above, you could canonicalize pages 1 and 2 to point to page 3. Search visibility of page 3 should improve.
Are You Ready To Bust the Myth of Duplicate Content?
Clearly, there are many variations of what constitutes duplicate content.
As you can tell, I don’t consider it to be a big deal as far as SEO is concerned, especially for republished content. The challenge is the work it takes to manage it on the front end and clean up any major problems caused by others.
If, after reading this, you’re still concerned about negative consequences from publishing duplicate content on platforms like LinkedIn, my advice is to publish your content on properties you own. Then, let others ask you for republishing rights.
What’s your take on duplicate content?

White Labeled and Branded Reports. Drag and Drop Editor. Automate your SEO, PPC, Social, Email, and Call Tracking Reporting.