

What is a Bot? Online Marketing Glossary
Bots are automated software that systematically travel the Internet and collect information about websites.
Bots, spiders or web crawlers are heavily used by search engines to figure out how high to display websites in search results. For instance, seeing how many high quality websites are linking to your website is one of the many important ranking factors bots can track.
Bots discover new web pages to visit or “crawl” by following links. Once a new webpage is discovered, details about the content and its relationship to other content is recorded. Bots also often revisit the same places to check for updates.
In the case of search engines, this data is collected in an index. Search engines serve relevant search results quickly by keeping an up to date index full of notes about which websites have relevant content on different topics.
Here is Matt Cutts of Google explaining how Google uses bots. Google’s web crawling bot is named Googlebot.
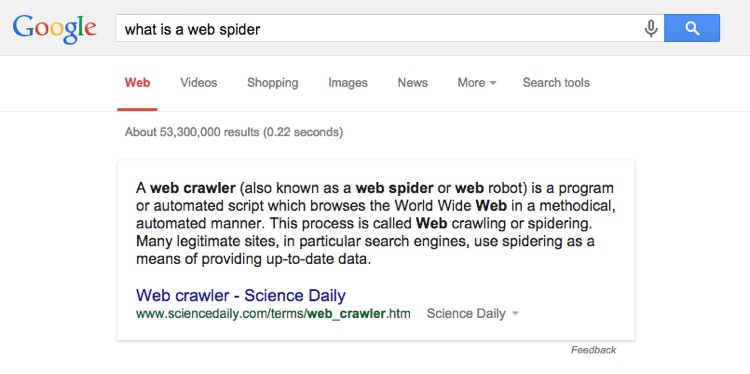
The use of bots also allow websites to automatically pull in information from other websites. This process is called web scraping. For example, when you search for “what is a web spider,” Google displays a definition pulled from ScienceDaily.com.
Search engines aren’t the only ones who use bots to gather insights. For instance, Raven’s Site Auditor uses bots to crawl websites and discover on-site SEO issues for customers.
Bots can be used for legitimate or nefarious reasons. For instance, spammers can use bots to crawl the Internet and collect email addresses to later send spam emails.
Website owners can ask all bots or specific ones not to crawl parts of their website by adding code to their website’s robots.txt file. Most mainstream bots comply but you can also attempt to ban certain bots by editing the .htaccess file associated with your website.
Google’s Controversial Use of Bots
Some marketers feel it’s unfair when search engines display larger chunks of their content within search results. The fear is that search engines are making money by serving ads related to content at the expense of content creators.
If visitors quickly find their answer in search results, they may not seek out the original source of the content. Dan Barker and other marketers have pointed out the irony of penalizing other websites for scrapping content while Google itself regularly scrapes content.
.@mattcutts I think I have spotted one, Matt. Note the similarities in the content text: pic.twitter.com/uHux3rK57f
— dan barker (@danbarker) February 27, 2014
However, other marketers see increased use of web scraping as an opportunity. Being prominently featured in search results can increase brand awareness, authority and trust among your target audience. If search engines highly trust your content, people may decide your content is trustworthy and worth of following as well.
Bot Resources
- Google’s Explanation of Crawling and Indexing
- How Web Crawling Works
- Top 10 Bots You Should Know About
- Limit Good Spiders with Your Robots.text File
- Block Bad Bots With Your .htaccess File
Synonyms
- Crawler
- Web Crawler
- Web Spider
- Googlebot